The new team member, a bot – chatOps (part 3)
Find out how you can tremendously simplify IT support no matter where or when. Using an always online Bot per technology now is simple, straightforward and free. You can even chat with it from your cell phone.
Continuing with this saga of posts. Now let’s dive into deep technical use cases. I will do it from a networking perspective just because it’s my main field of knowledge, but since Ansible and Salt are multiplatform, the following use cases are multi-platform in a single playbook.
If you want to know the history of how I got here, you can check out my previous articles here in LinkedIn or at https://adriangiacometti.net
Just a reminder, this is personal development in which by using Python I’m making interfaces to integrate Slack, Ansible and Salt, in a real running environment, this isn’t just to talk with made-up pictures, this is the actual output of the code.
Let’s jump to the fun part!
Many times it would be great to have a teammate in the office to throw some command to check some service status and let you know the outcome. Sometimes while “taking a walk” a new incident occurs, or you get an email to check on something, or maybe you just remember something after leaving the office, etc. Now you can count on a new team member, a bot. You can chat with “him” on your cell phone asking to do some tests and give you back a response in seconds in the most simple way and without involving a 10 minutes call, opening a support ticket, the waiting, etc. And potentially saving you from going back to the office or connect your PC as soon as you come back home. Or even delaying the work of another team!
Don’t lose the perspective about the effort and time this checks would take, and of course, this bot is not only for you to use, everybody could use it and just after seeing a negative result they may need to call you, because let’s face it, many times someone calls you and the problem is not in the network, and your support was just to give some guidance, ok, the bot can do that as a team member. 🙂
Hence some of these basic bot tests would be directly published to end-users and then avoid losing time by calling other people for help.
Now let’s go to the use cases.
Case 1: A simple one. You have configured the network 2 days ago to support a new service, but when the server team is deploying and testing, they are having problems to connect to the cloud or private service. What do they/you need to test from the server perspective?
Why the server perspective? Because it’s the end-user point of view. Many times from the network perspective it seems OK but not from the server point of view, which in the end, is the most important point, the real service you provide.
Let’s say that we need to test from the real server:
- DNS resolution
- Ping
- Traceroute
- TCP connect to port 80
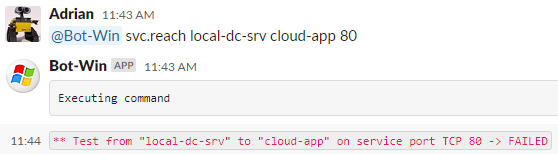
OK, something went wrong. Let’s see what it was by just adding the “detailed” keyword at the end of the same command.
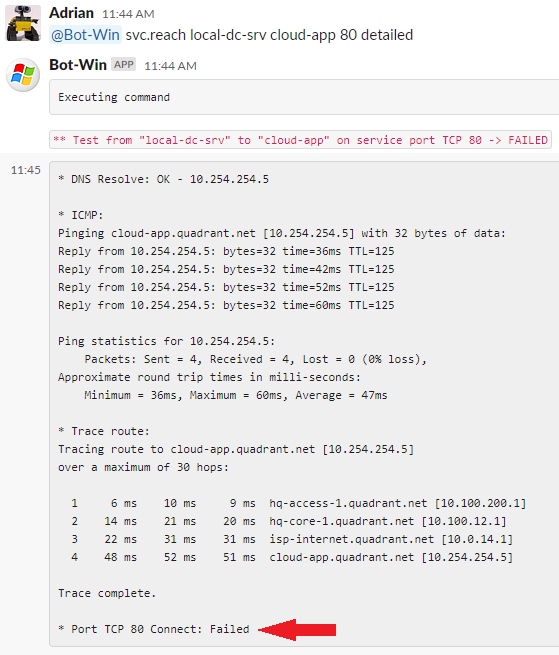
Great! Everything looks OK, but the TCP port is blocked at some Firewall or maybe the service at the destination is down or listening on a different port.
For many cases, this normally would require an unnecessary loss of time by opening a ticket and contact support just to check before you even start to solve the problem if there is one.
As you can see, in 1 minute, the bot has performed the basic tests directly on the server. The next step would be to check the server status like I already showed you in the previous post, and ask the bot to check if there is a Firewall ACL.
This kind of basic test is not only useful to you, but any system support should also be able to have access to these kinds of functionalities. And this is how in a couple of minutes, you have a common language, a shareable output, and self-service.
Case 2: Of course at some point, you will need to check that the new service is accessible from everywhere in the company. Most common examples:
- While migrating internal services to the cloud
- A new cloud or internal service needs to be accessed from all the company sites
- Check that all the service layers can reach each other (Front-End to Back-End)
- All the DB servers of a cluster can see each other for synchronization purposes
- All the servers of a Windows Active Directory Forest are reachable between them
This use case is invaluable!
Massively test reachability to the new cloud service on HTTP port, from all your servers and sites.
(In this case, I didn’t advertise the Cloud subnet in one of the company sites to force the error. Also notice that for the source I’m using a group name “src=windows” instead of a specific server.)
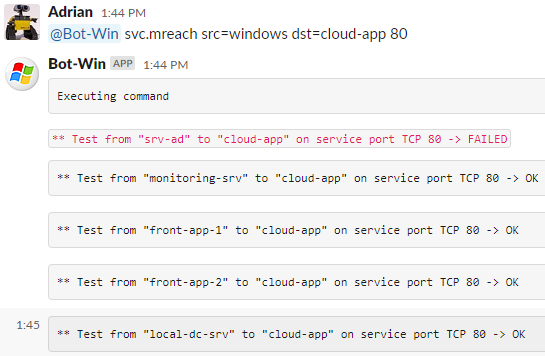
Let’s see in detail the error lines that show this common issue.
The first part of the picture shows one server tested OK, and the second part one server tested not OK. In the details, you can see Ping, Traceroute, and TCP connect are not working and having an incomplete traceroute might indicate a routing problem or ACL.

So, you already know that most of the sites are OK to start using this new service. You already have a standard check procedure that anyone can use, and regarding the issue, you already have identified which is the problem. Now you only need to fix it knowing exactly where to start.
Case 3: This next use case is the reason why I started to think about this solution.
When doing big core network changes, like linking a new Datacenter or deploying a multi-DC architecture, on D-day, there is a big deal about controlling that all the internal routes are in place and all the sites are reachable. You can try to check route prefixes, but this use case has a holistic point of view and can be fully automated using the real end-user scenario.
This kind of test is virtually impossible to be performed by humans because it will take a lot of time and the involvement of different teams. So, let’s automate it!
We need a reachability test, from all the inventory to all the inventory.
Yes! Test that every server-group and every network-device-group can reach the other one.
(Notice the syntax of the command to indicate groups instead of specific servers, “src=windows,network” to “dst=windows,network”)
I’ve never seen anything like this before.
With this simple, fast, and massive check you are testing from the real devices to the real devices, nothing involved in the middle, no agents, no extra monitoring software.
With an inventory of 3x windows servers and 6x network devices, I did 81 reachability tests, in only 2 minutes!
Plus you can see how each bot is answering back for their part of the job.
(I will crop the image to make it smaller)
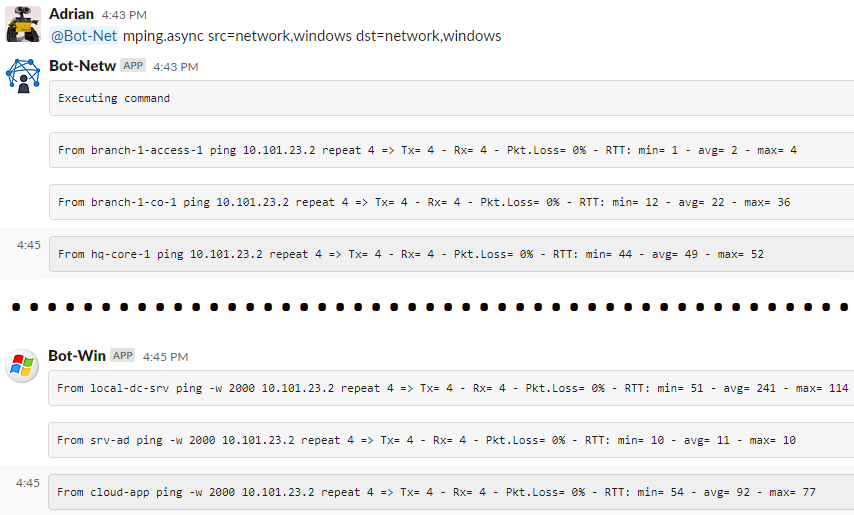
This could be part of your pre and post changes checks and evidence, and at the same time, you are publishing the tests so the whole team can see where are you standing during the activities.
Isn’t this awesome?!
In the posts to come, I will show the Architecture and Security of the solution, and a couple of interesting use cases that I’m discovering as I move forward in this automation adventure (from chatOps to botOps).
Sharing of ideas, questions, suggestions, etc. are more than welcome.
You can read these posts and get a copy by e-mail as soon as I publish them at https://adriangiacometti.net