Fast and basic DRP solution (part 2)
In the previous post, I oversimplified the situation just for an easy onboarding to the case.
Now it’s time to go into deeper details.
First I will describe a bit more the design I had for this case, with my context and constraints, and then a great option to add dynamic routing (based on some talks with Ivan Pepelnjak and Nicola Modena, thanks for that gentlemen). By the end of the post, you will have a pretty complete rationale that might be helpful. Then it’s your job to find the right balance for your scenario.
What I ask from you is to please please please contextualize the solution, there is no one-fit-all solution for this kind of complex scenarios involving the whole IT ecosystem of a company (technical and non-technical aspects), and therefore, there are only good solutions for specific contexts. If there were a perfect solution I wouldn’t be posting something original, I would be sharing some other link/PPT, and even so, there are thousands of variants.
So, from the beginning, short situation: a big company with an on-prem regional Datacenter serving several countries, dual ISP international MPLS links, several remote offices across the region, shared VoIP services everywhere, hundreds of servers, a ton of hypercomplex and related stacks of services, thousands of internal users, hundreds of business partners, thousands of internet customer user, blah blah blah full-blown international enterprise architecture.
Requirements:
- we can not change the server’s IP address
- we want to be able to monitor and test the DRP without disrupting normal operations
- since we are already at the top of man work capacity the solution can’t have any changes to the actual production ecosystem (so it has to be almost transparent)
- and make it happen in 6 months.
Also at the DRP site, there were already a couple of running services, so the site was already connected to the regional MPLS.
Like Nicola Modena pointed out to me, this is going somewhere from Disaster Recovery (DR) to Business Continuity (BC). In a DR situation, the 2nd Datacenter is not providing any service, but in BC it can already provide basic services.
So, the main business constraint was time: networking has to propose a solution in less than a month so the other IT teams can start to design their solution, then add everything to the budget, then send it to approval while we all design together, and in parallel, start the procurement process. Inconsistencies… “deal with them later”.
I picture this for myself:
Office 1: Hey, I need a DRP, yes sir, do it for yesterday, yes sir.
Office 2: the boss wants a DRP for tomorrow, deal with it.
Actually, this doesn’t sound that weird, we are used to this kind of pushy situation, right? That is why our profession exists, use your skills to solve this fast, tomorrow is too late (I love challenges, challenge accepted!)
(Notice that I haven’t even talked about, “hey! what business process (=IT systems) do we have to include in the DRP?”… there goes 2 months of weird meetings)
My first thought was “What about LISP?”. So I did some tech research, it sounded like a good fit but with almost no documentation. Then I went to vendors and colleagues and I couldn’t find any working implementation. So, LISP is not an option. As an architect, I can’t propose a solution that might work but I don’t know who is gonna be able to operate it.
I have to give a solution that is viable, satisfies the requirements, and that the company can operate from day 1 (in that order).
So in my previous post I got to this high-level design.
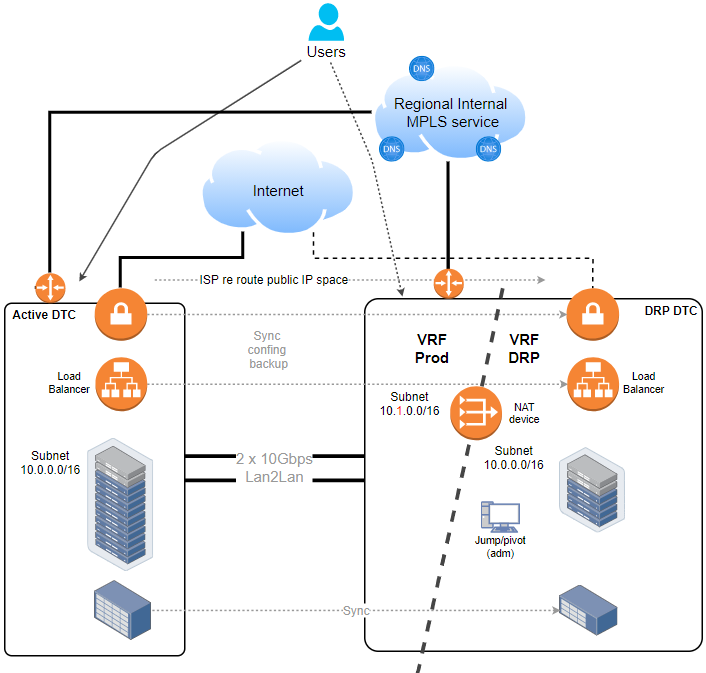
While business applications have to remain isolated at the DRP VRF, basic services like DNS, DHCP, NTP, SMTP, AD, etc, can be allocated at Prod VRF, in that way the recovery process can focus only on real business applications.
Another comment that I received: “asking the ISP to re-route the public IP space to the DRP site is suboptimal and out of your reach”.
Yes! but first, I can’t change the public IP addresses, similar restriction as with VMs right? because:
- no time to deal with updating a hundred remote business partners’ VPN devices, with different vendors, from the best to the worst, with and without support for secondary IP VPN peers.
- for published services to the internet do a full update name resolution to the DRP IP address space. It’s doable? technically yes. You can assess all the DNS records without missing any of all the domains you might have, not easy. Then some kind of update based on external probing? yes. It is practical? no. First I can’t solve in time the previous VPNs bullet, then I don’t have time to deal with DNS refreshing, timeouts, etc
And second, there was no BGP with the ISPs for Internet links. Not difficult to have and I could even just have a default route. But we need engineering time to work on the inner part of the solution.
So, yes, reroute the IP address space, and problem solved, it will work as soon as the IP address space is rerouted. Being the same ISP, it shouldn’t have more delay than the operator typing the commands to reroute a subnet.
In our case, we were already using F5 devices, so the NATing and Load Balancing was solved in one place.
Now, since Server admins and Application developers can not change the IP address, then NAT will solve that, and thus a couple of agreements had to be made.
As a trade-off for having those servers in the DRP VRF reachable, we have to introduce NAT, so:
- We will only NAT main IP services like the VIP of the load balancer (and not every VM), and a pivot server so they can access the infrastructure locally (has to be local because of the overlapping IP address).
- In extreme cases, if a server from Prod VRF has to talk directly with a server in the DRP VRF, then we have to do double NAT (again because of overlapping IPs). There were not many cases, that was good.
Later, for remote internal user access, we used a cluster of F5 GTM we already had distributed at main regional sites.
Access from remote users is managed by name resolution, as usual:
- Production-APP-1 will resolve IP-1 (10.0.0.10)
- DRP-APP-1 will resolve IP-DRP-1 (10.1.0.10)
- Hence, both Prod and DRP Application are reachable
- In the event of a disaster, the name resolution probings will automatically redirect the users by resolving Production-APP-1 to the DRP at IP-DRP-1
So, by now I only used two old and basic concepts, VRF and NAT. Isn’t it awesome to solve this complex scenario with just that?!
Ok, let’s continue. What about dynamic routing? In my scenario, it was not feasible to do it given my time constraints. I already mention the internet side. Now for the intranet, the scenario was different, we already had dual ISP links with dual routers. BUT, the BGP configuration was very complex and hypercritical. The links were used sometimes for backup and some other times for load balance. With VoIP services and several PBXs all over the region with Call Centers sharing the calls. So, this is when the restrictions came into play again: make it fast and transparent. In my case, not the moment to play with BGP.
But if you can do it, this is where Nicola’s approach is beautiful and you even can find a balance that might suit your context better.
Let’s add some dynamic routing!
Adding dynamic routing this whole thing is the way to go.
On the Internet side is not that complicated to speak BGP with the ISP. Just keep it simple. You may not need to know the whole internet route table if you are not an ISP.
Now for the Intranet side, well, it’s already managed by you, so you can add to the equation Nicola’s proposal: use ANOTHER old fellow MP-BGP with RT/RD, great idea!
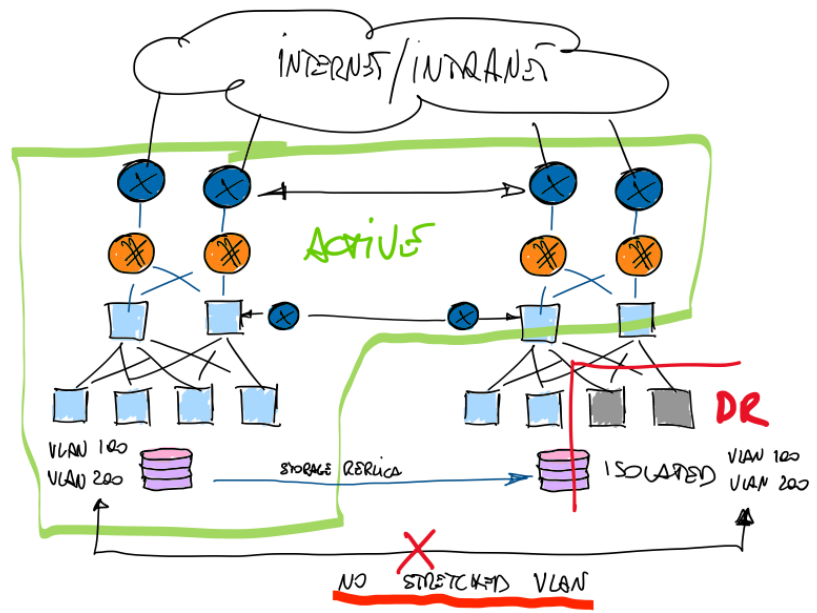
In order to activate the DR or better said, to be able to access the DR VMs, he only needs to play with MP-BGP and update RT/RD prefixes between the VRFs. Then the new location of the subnets will be published to the rest of the network.
Once routes are redistributed (do automation here), networking is out of the picture. ALL VMs can be accessed even without NAT. But at this point, the original subnets/VMs are only accessible at DRP VRF. It looks like an all-or-nothing scenario. But if you do a mix with NAT, you can test the DRP without disrupting the services.
Awesome! now you find your balance between NAT and BGP. Because you CAN have one, both or a mix.
Applications team vs Servers team vs Networking team
The eternal dispute. The applications team can’t change the whole code in one day (it takes several months and problems will arise), and the Servers team has to follow the applications team and maybe add some of their needs. Finally, the networking team can’t do magic either.
Small or “new era” companies might be able to not have this kind of situations, but, big companies have a BIG web of interrelated applications mixed with new stuff, old stuff, and WEIRD stuff.
Look at this. It is a data model from Cisco ACI: it has several filters and it is only showing a portion of the Datacenter flows. Look how complicated things can be.
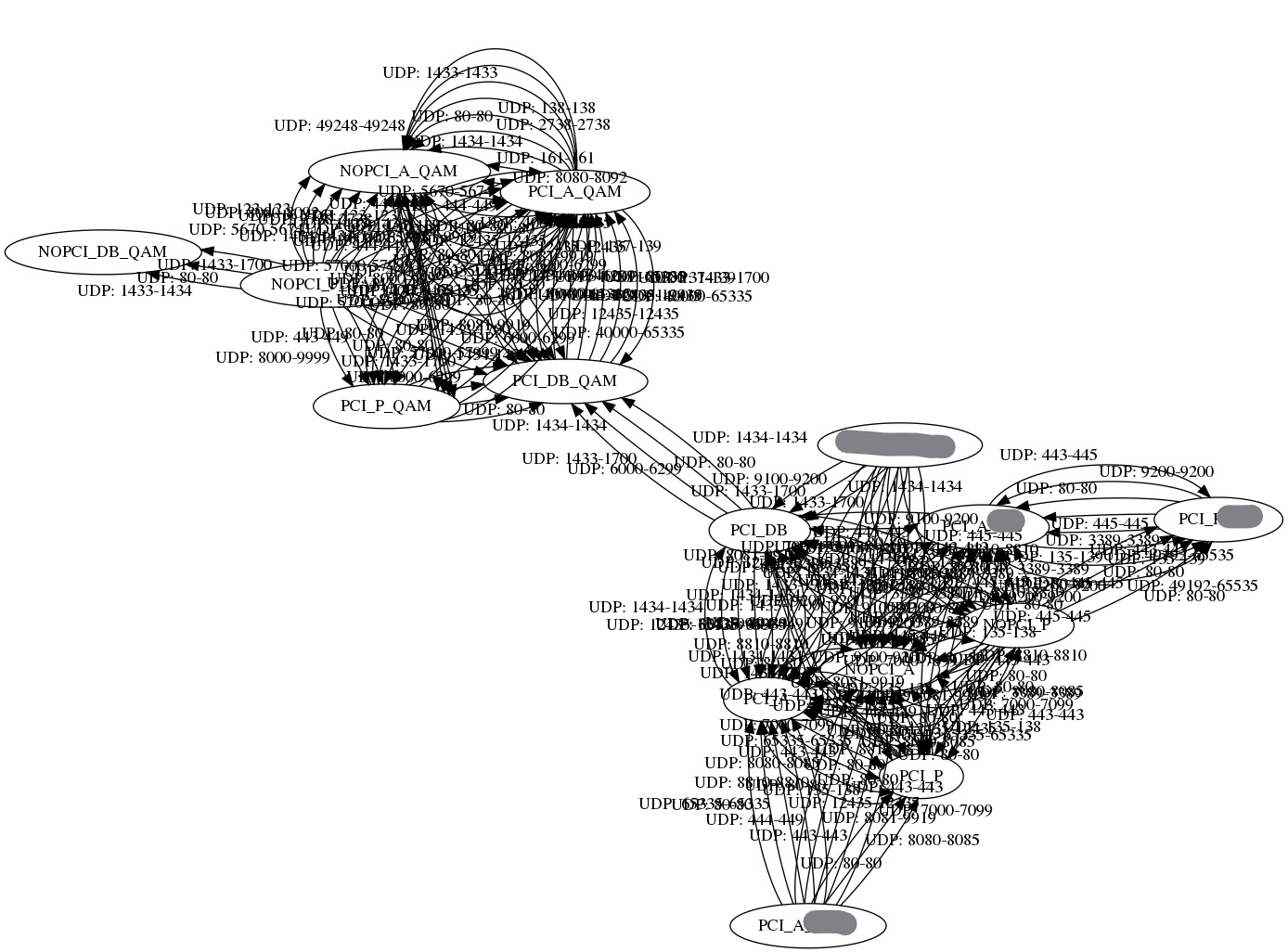
(I used this in a previous post where with Python I extracted the data model from Cisco ACI and transformed it into Terraform in order to deploy it in Oracle OCI, in minutes!)
And we just can’t stop giving real benefits or deliverables to the real business. After all a DRP/BC is not something that will make the company earn more money, in fact, it will be expensive and it will not actually produce, it will be there just in case something very unlikely to happen actually happens.
So, back to the IT guys and, differences aside, let’s be honest. If you ever coded you know that some years ago while trying something you hardcoded something, then a new urgent requirement came in, and then another one, and then another technology change (yes we change things a lot!), and this is how technical debt stale there forever. It is just the way it goes. We have that in any field. In networking we hard code every IP at every router or switch right? What if someone asks you to move a switch to another site without changing the IP address? or move a virtual firewall VM to another site? It will be the same scenario of “I can’t do that I have to change the IPs”.
Now with IaC approaches, we are trying to evolve that a bit and we even pay more attention to DNS. It’s just not easy to change an IP anywhere (fast-talking here, do not judge, just get a general idea).
But, interestingly this time, from a critical situation where networking can not resolve the problem of duplicated addressing even with good intended solutions proposed by other teams like stretched VLAN, etc., we got to a situation where networking proposed a solution and we all started to work towards the objective. That was nice.
Final words
So basically, it is not the best situation but we can do this!
Have a duplicated Datacenter with not too many changes to the whole pile of IT systems that supports the real business.
I will leave an open question because I can foresee this happening to me in the future…
“Can we do this DRP/BC… ON the cloud?” mmm OMG… maybe, but I should say no… or please no?! 🙂
I hope you enjoyed reading, I know it was a long post so thank you.
Have a good day!
Adrián.-
Hi Adrian,
Great writing and from the network perspective it’s all true.
The only thing against it is an increased cost. To have it working, a company would need to keep a hot-standby DRP DC. Not only the data, but actually the entire compute power should be replicated in the DRP DC.
But yes, this last part is not a network infrastructure topic, rather a business decision.
Hi Calin,
Yes! You are entirely right, thanks for noticing that!
As you said, it is a business decision and it is an expensive one.
Having a DRP is never cheap.
Imagine how challenging it was for me to have this idea of wasted resources in my mind while in the design phase.
I talked about this with all the stakeholders. But in the end, it was getting too complex as a whole, I mean first, having a simple DRP (MAIN objective) and all the changes it involves, and then take another step to make it active-active (NOT in the roadmap).
Making it active-active is not an easy job for App and DB teams, there are several synchronization aspects at DB and App level, and that would have taken a looong extra time.
Because of this, the business decision was to stop and have a DRP in the required timeframe.
This is why I ended the first post with the question “how far we are from active-active?”.
And also this is why I like the idea of being a reachable DRP. Just to suggest “hey! from a networking perspective, we can use the compute power we are already paying for”.
As you can see, this design leaves the networking infrastructure ready to take the next step. A compatible infrastructure to go for an active-active scenario (even with duplicated IP addressing!) 😉
Cheers