Some time ago I was asked to design the networking part as a basic DRP solution with the aim to fulfill an audit requirement, basically, the DRP has to cover the scenario of the main Datacenter going completely offline. So, all or nothing scenario, and only the main applications were covered. The secondary site would be an already existing site in the same metropolitan area.
It was very time-constrained, so there were several aspects to overcome, the most important ones were related to IP addressing.
We can not change the VPN concentrator public IP. There were hundreds of VPNs connecting to business partners, and going one by one it would have taken months.
From the servers and applications teams. We can not change IP addresses of the VMs, since there are several hardcoded IPs in the applications, and start solving that one point would have taken a lot of time and effort of several teams.
Sounds familiar?
Well, the design, in the end, was not as crazy nor as impossible as I imagined. It was actually relatively easy to deploy and it worked just fine.
Let’s start by decomposing the problem into smaller blocks
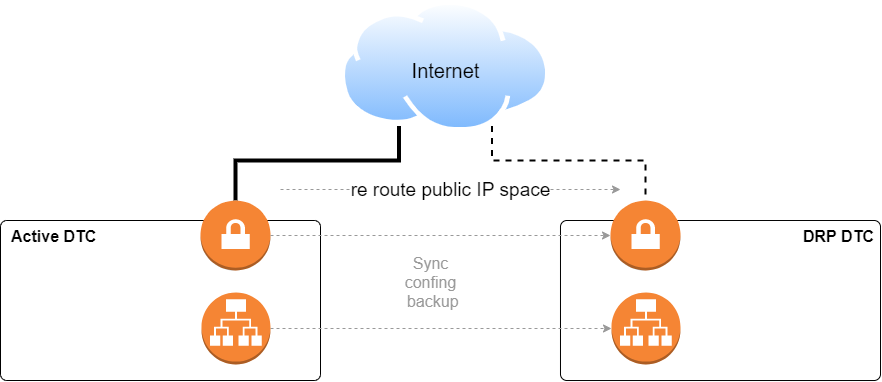
Since at both sites (active and DRP), the ISP had a POP, for the VPN concentrator we just agreed with the ISP that in case of emergency it would reroute our public IP space to the DRP location. We added a new VPN concentrator, the same model as the one in production but with less processing power, and just kept a backup of the configuration file stored in a server at the DRP site and pushed it periodically to the DRP network devices. In this way, if something happens we just need to wait for the ISP to reroute the public IP addresses.
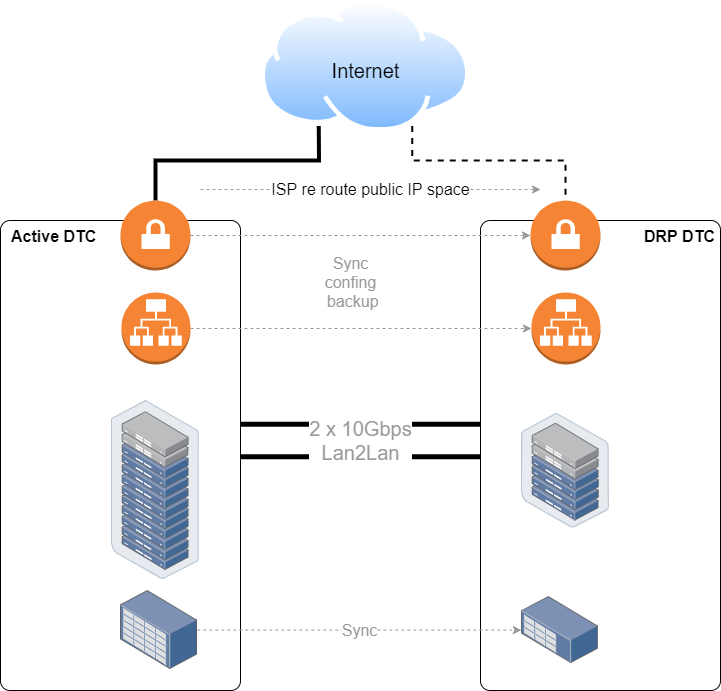
We also had load balancers, which were also backed up and in sync with standby ones at the DRP.
The server teams will maintain replicas of VMs and DBs at the storage level, site against site. For these replicas, we needed 10Gbps Lan2Lan links, which in metropolitan areas are not as expensive as MPLS (think about these Lan2Lan as cheap BW technology, not as Layer2 links to pass VLANs, in fact, we used routed interfaces). The most expensive component was clearly the storage, then the servers, and networking just 15% of the budget (links included).
Those two links will be also used for normal IP communication between the environments.
Now from the servers IP address point of view is where it gets interesting. Since by now no IP address was changed, we can say everything would work fine as independent replicated sites, VMs, load balancers, VPNs, Internet, etc.
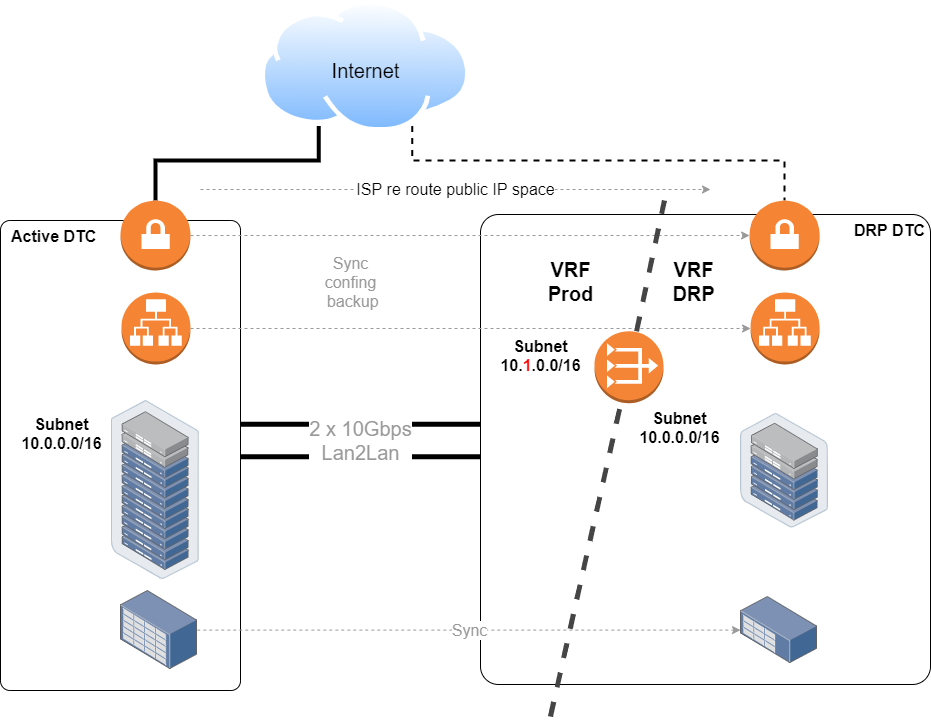
So how to maintain connectivity to production and DRP environments which had the same IP address? Well, this is where the old fellows VRF and NAT come into play.
The replicated VMs subnets will be in a DRP VRF, so that is ok, old stuff, and it works.
Both VRFs, production and DRP, were connected with a router/NAT device.
At the NAT device we only NATed the services IPs, those needed and exposed to end-users, and for infrastructure and remote management kind of stuff, we set up pivot servers inside the DRP VRF.
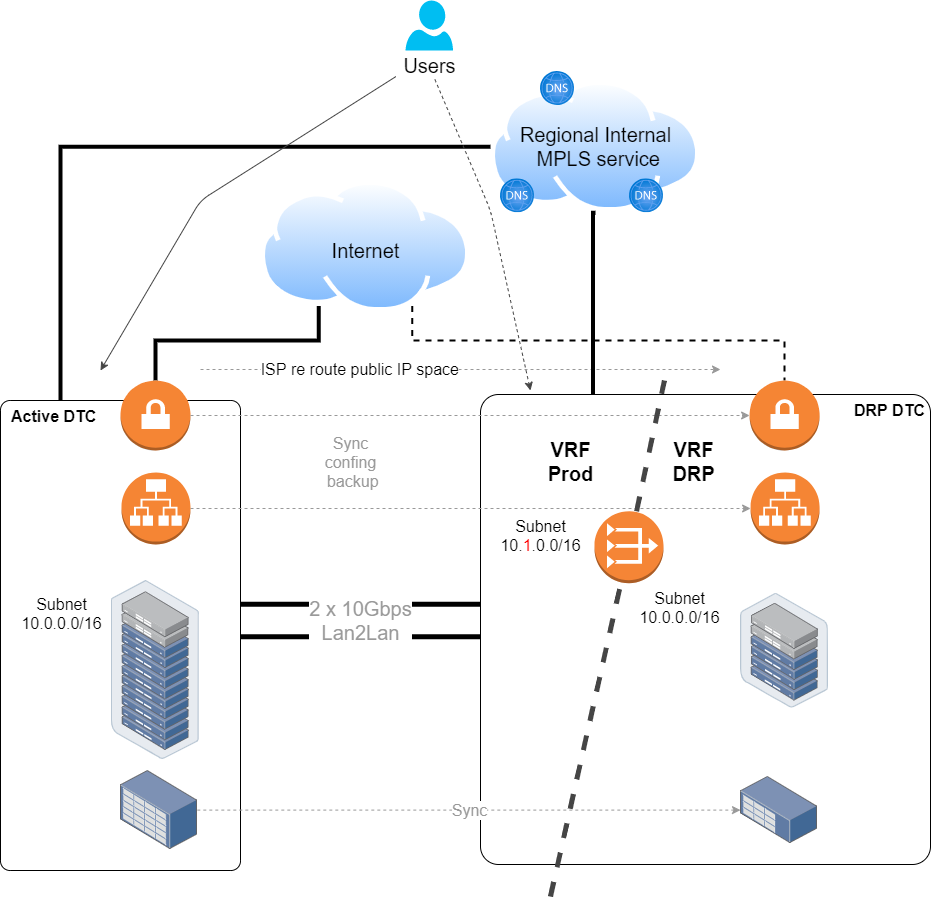
And finalizing since we had a DNS infrastructure across all the regional sites, we implemented probes based DNS service rerouting.
I know that the server and application teams had some other problems to overcome because of this requirement of maintaining the same IP address, but eventually, they made it work.
It is not the most beautiful design that I have done, but it worked, and actually, it made me think about:
Is technology evolving or is just a pile of old stuff rebranded by new developers?
Why haven’t I seen these scenarios before? I know it might sound weird, but it is completely viable as a basic case of study.
How far away were we from having an active-active scenario?